¿Qué es Machine Learning?
El aprendizaje automático (Machine Learning) es una herramienta utilizada por la minería de datos para obtener conocimiento de los datos que previamente se han obtenido. La minería de datos incluye muchas actividades previas al trabajo de extracción de patrones y creación de modelos, incluyendo las de data warehousing, procesamiento de datos, obtención de datos de fuentes externas, etc.
Normalmente el proceso de minería de datos suele seguir las siguientes etapas, denominadas KDD (“Knowledge Discovery in Databases” process) (más información sobre KDD):
- Determinar las fuentes de información que pueden ser útiles y dónde conseguirlas.
- Diseñar el esquema de un almacén de datos (data warehouse) que consiga unificar de manera operativa toda la información recogida.
- Implantación del almacén de datos que permita la “navegación” y visualización previa de sus datos.
- Selección, limpieza y transformación de los datos.
- Seleccionar y aplicar el método de minería de datos apropiado, que servirá para obtener patrones de los datos.
- Evaluación, interpretación, transformación y representación de los patrones extraídos.
- Comunicación y uso del nuevo conocimiento.
También podemos emplear el modelo CRISP-DM (Cross Industry Standard Process for Data Mining) que es más completo, amplio y utilizado. Este modelo abarca desde tareas relacionadas con comprender y hacer hipótesis sobre el negocio, hasta las tareas relacionadas con el tratamiento de los datos y aprendizaje automático (más información sobre CRISP-DM).
Un ejemplo gráfico de Machine Learning
Muchos algoritmos de aprendizaje automático se utilizan para clasificar. Es decir, dada una población de instancias se quieren dividir en dos o más clases disjuntas. Consideremos el siguiente ejemplo:
- Tenemos tres bancos que quieren clasificar a sus clientes.
- Queremos clasificar a los clientes de acuerdo a si tienen posibilidad de impago de un préstamo, y tenemos una base de datos de 1000 clientes que ya están etiquetados, es decir, ya sabemos de antemano si han impagado o no.
- Hay dos variables que los describen: tiempo de antigüedad en el banco y número de préstamos aprobados, y que hemos determinado que son interesantes.
Podríamos tener varias situaciones al tratar de visualizar el conjunto de datos.
Caso 1
En el primer caso, si dibujamos los clientes del primer banco como puntos, con la antigüedad en la X y el número de préstamos aprobados en la Y, y pintamos de dos colores diferentes los clientes que han devuelto el préstamo y los que no lo han hecho, nos encontramos con lo siguiente:

En este caso con una única línea recta se pueden separar claramente las dos clases. Este es un caso en que un clasificador lineal podrá resolver fácilmente el problema planteado.
Caso 2
En el segundo banco, hacemos el mismo dibujo, pero el resultado que obtuvimos es muy distinto:
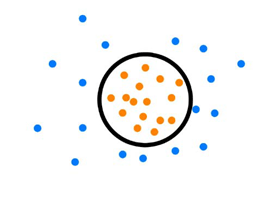
Vemos que en este caso, no se puede separar bien a los puntos con una línea recta, sin embargo, sí se podría trazar un círculo que puede hacerlo. Este es un caso donde claramente las clases son separables con esas variables, pero no valdría un modelo lineal.
Caso 3
Por último hacemos lo mismo con los datos de los clientes del tercer banco y en este caso tenemos el siguiente resultado:
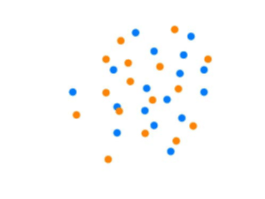
Este es un caso donde no parece que las clases puedan separarse claramente, con las variables consideradas. Esto nos indica que quizá esas variables no sean las relevantes para clasificar a los clientes de ese banco.
En conclusión, los datos, sus distribuciones y la selección de variables son fundamentales para obtener buenos modelos con el aprendizaje automático. Además, aun cuando las variables sean relevantes, es importante seleccionar bien el algoritmo, como vimos en la diferencia de los casos 1 y 2.
Aprendizaje supervisado y no supervisado
Hay muchas formas de clasificar los algoritmos de aprendizaje automático, pero la más amplia sería clasificarlos en algoritmos de aprendizaje supervisado y no supervisado.
En el aprendizaje supervisado, nuestros datos están etiquetados, es decir, cada instancia de nuestro conjunto de datos tiene un atributo que es el que clasifica a esa instancia en dos o más clases. Por ejemplo, si tenemos un conjunto de datos de clientes de un banco, podríamos querer tener un modelo de impago de los mismos. Entonces tendríamos en nuestro conjunto de datos:
- Atributos de entrada: podrían ser en el ejemplo: el tipo de préstamo pedido, la edad, fuente de ingreso, si está casado, nivel de estudios, otros productos financieros que tenga, etc.
- Un atributo que es la “salida”, etiqueta u objetivo, que en este caso sería el campo que indicase si ese cliente ha impagado o no el préstamo.
Así, los algoritmos “aprenden” tratando de buscar diferencias entre las características de las instancias de alumnos que abandonaron el estudio y los que no. Lo fundamental de estas técnicas es que los datos tienen que venir previamente clasificados para realizar el entrenamiento.
En el caso del aprendizaje no supervisado, no se tiene (o no se considera) esa etiqueta que clasifica a priori las instancias. Por ejemplo, podríamos querer simplemente buscar segmentos de clientes, es decir, buscar grupos de clientes homogéneos para crear campañas publicitarias personalizadas, pero no sabemos a priori cuántos grupos habrá ni sus características. Este es un ejemplo de “agrupamiento” (Clustering).
Es importante entender que el uso de aprendizaje supervisado o no supervisado depende de los objetivos de nuestro estudio, y no solo del dataset. Por ejemplo podríamos utilizar también aprendizaje no supervisado en un dataset etiquetado para buscar otras posibles relaciones que se encuentren en dichos datos y no sea la definida por el campo etiquetado de salida.